Today, Large Language Models (LLMs) have become a major part of modern technology. Well-known examples include Claude Sonnet, Claude Opus, OpenAI GPT models, and Gemini.
A common question is: How are these models built, and what is the underlying technology behind them?
The answer lies in neural networks.
Neural networks form the core foundation of modern LLMs, enabling them to learn patterns, process language, and generate human-like responses.
A neural network is a machine-learning model inspired by how the human brain works.
Our brain is made of billions of neurons. Each neuron receives signals, processes them, and then passes signals forward to other neurons. Over time, the brain becomes better at tasks by strengthening or weakening the connections between neurons — this is basically how learning happens.
A neural network copies this idea in a simplified mathematical way.
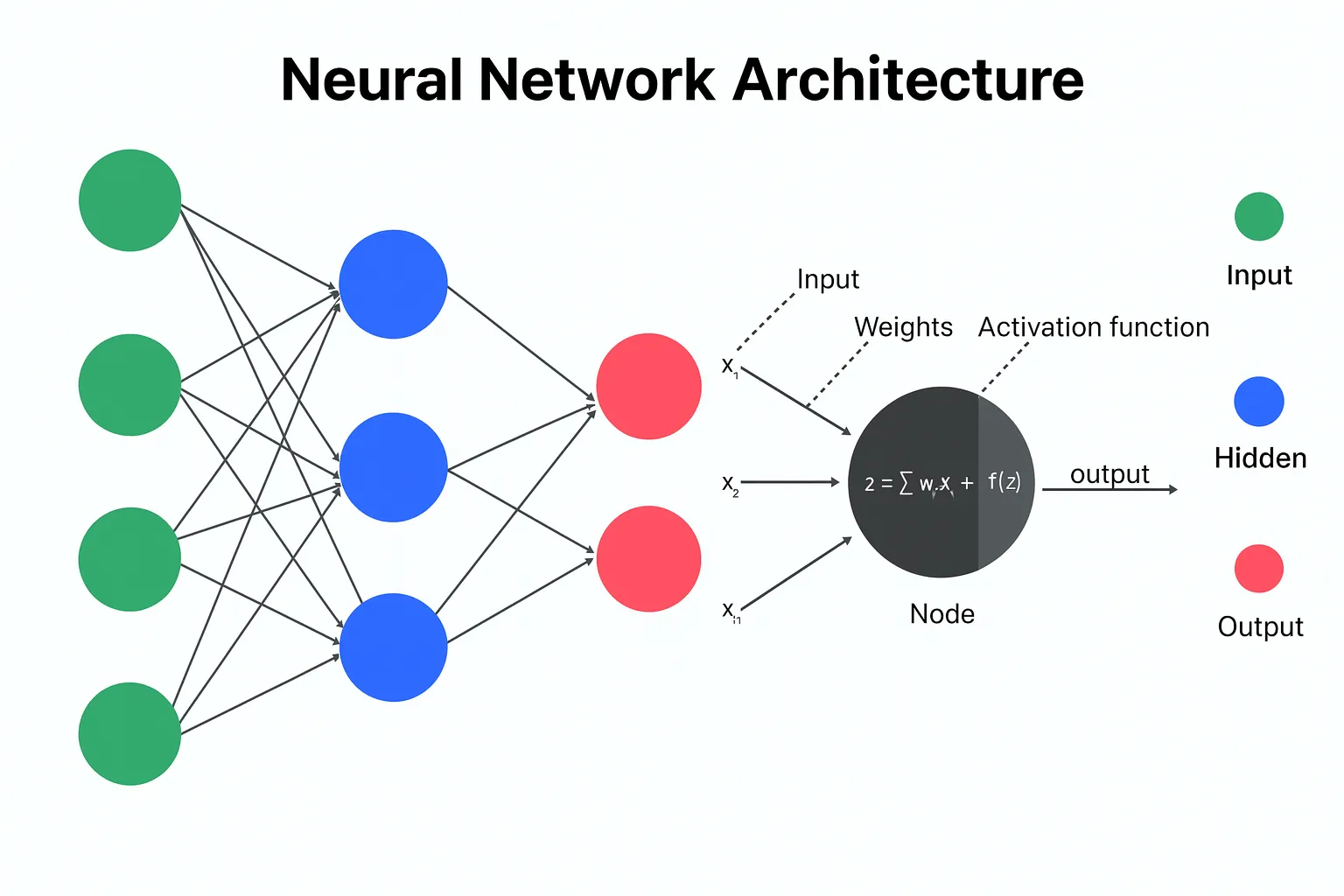
Neurons in the Brain vs “Neurons” in AI
In AI, a “neuron” is not a real biological cell. It’s a small mathematical unit that:
Receives numbers as inputs (like signals coming in)
Multiplies them by weights (how strong each connection is)
Adds a bias (an adjustment term)
Passes the result through an activation function (decides what to send forward)
So you can imagine:
Inputs = signals coming into a neuron
Weights = strength of connections (how important a signal is)
Activation = whether the neuron “fires” strongly or weakly
Every deep neural network is a neural network, but not every neural network is deep.
That means models like GPT-style systems are not just “normal” neural networks — they are usually very large, deep neural networks trained on huge amounts of text data.
