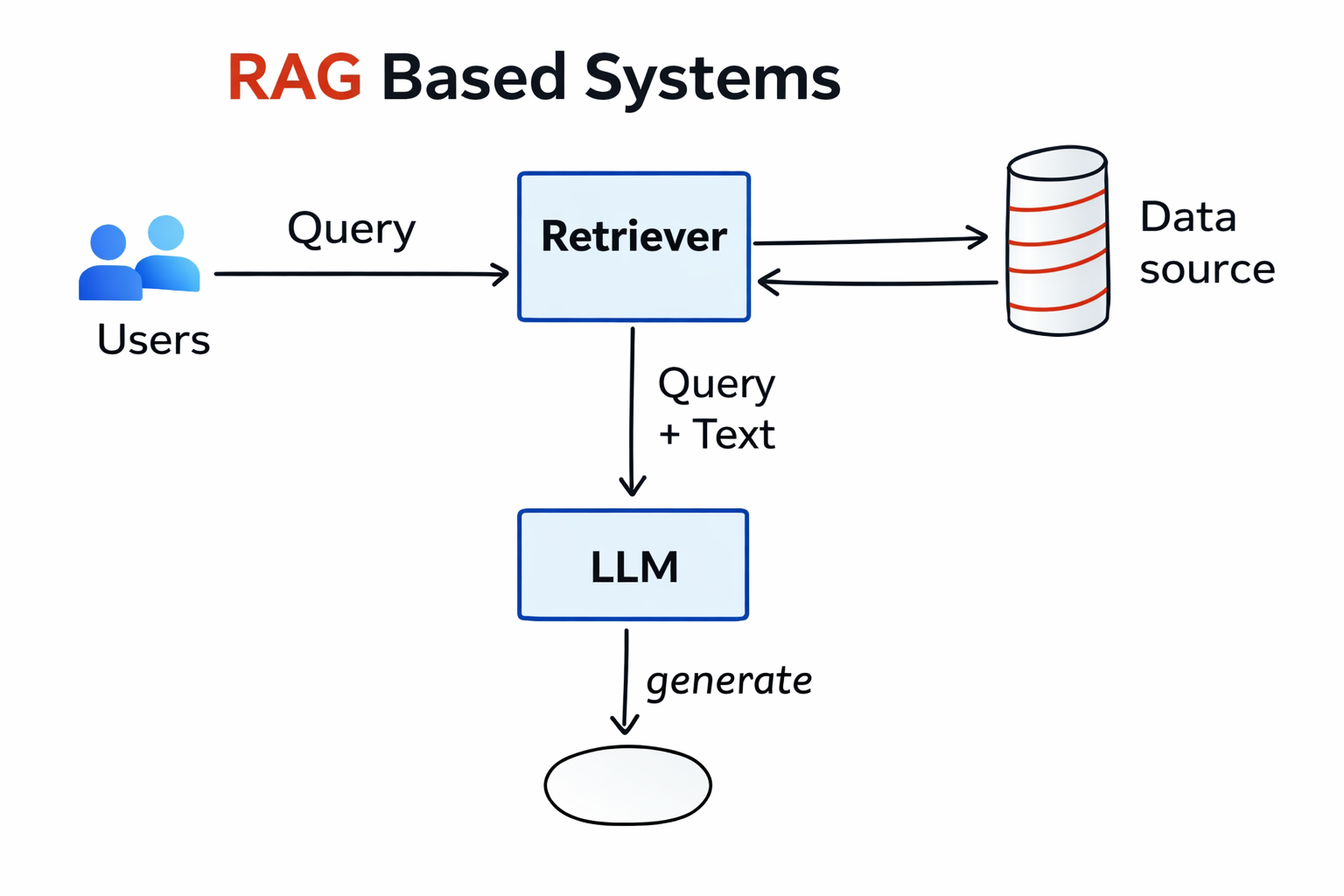
Retrieval-Augmented Generation (RAG) is an AI framework that improves Large Language Model (LLM) accuracy and relevance by fetching data from trusted, external, or proprietary knowledge bases before generating a response.
RAG is not only vector db+ LLM, Real RAG quality mostly depends on:
document quality
chunking quality
retrieval quality
prompt quality
filtering/reranking
If we asked our LLM like is virtat kholi playing next match?
LLM are not upto date
suppose TCS revenue in 2022-2023?
LLM will give Very generic response even the document is available on internet.
suppose if we have a pdf report, if i upload the report in somewhere.
if we have sales report in this pdf, so to overcome LLM problem overcome we will consider RAG, then we will get exact answer from our model because we train it on pdf.
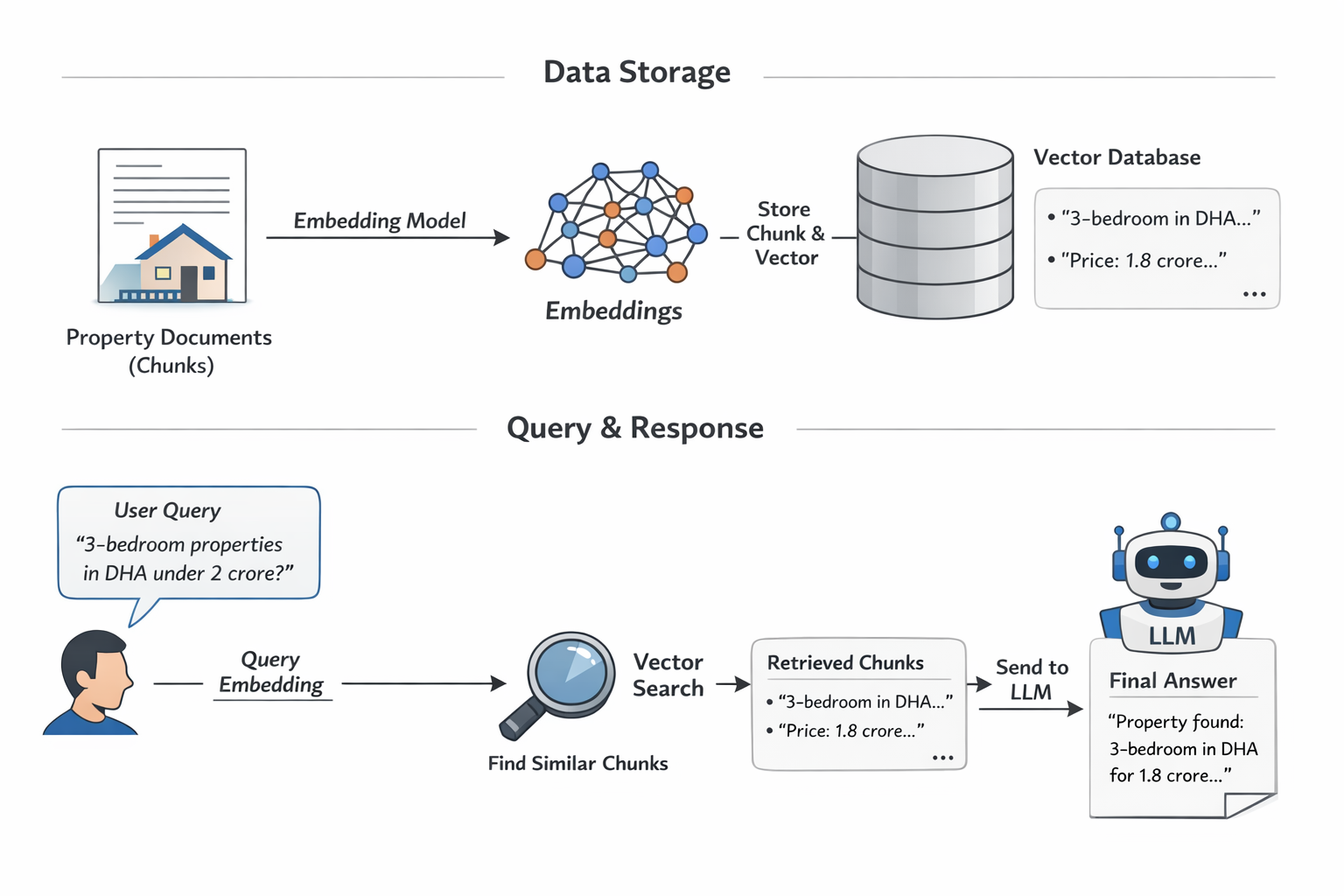
suppose we have a book, if we put this is in database, so we augment model with this book. so we store the text in form of embeding in vector db. the embeding is important,each chunk is converted into a vector by an embedding model. It takes text and maps it into a high-dimensional space so that:
similar meaning = close vectors
different meaning = far vectors
This is why vector DB can search by meaning, not only exact words
RAG minimizes AI hallucinations(Wrong confident answer) by grounding answers in retrieved, trusted sources.
But vector db design,architect matter a lot, like architectural constrains depends on use cases.
Embeddings in RAG
Embeddings are numerical representations (vectors) of text that capture semantic meaning. In a RAG pipeline, they serve as the bridge between user queries and your data.
- Vectorization: Before retrieval, documents are broken into chunks and converted into embeddings using models like BERT or OpenAI’s Ada.
The Process
- Generate Embeddings: First, you need an embedding model (e.g., from OpenAI, Hugging Face, or Cohere) to convert your raw data (text, images, audio) into high-dimensional numerical vectors.
- Choose a Vector Database: Select a database designed to handle high-dimensional vectors efficiently. Options include dedicated vector databases like Pinecone, Chroma, and Milvus, or traditional databases with vector search capabilities via extensions like pgvector for PostgreSQL or built-in features in MongoDB Atlas, Amazon OpenSearch Service, and Google Cloud Firestore.
- Index and Store: The generated vectors are then "upserted" (inserted or updated) into the vector database. The database uses specialized indexing algorithms, such as HNSW or IVFFlat, to organize the vectors for fast approximate nearest neighbor (ANN) search.
- Add Metadata (Optional but Recommended): Store relevant metadata (e.g., the original text chunk, a document ID, or timestamps) alongside the vector. This allows for hybrid searches that combine semantic similarity with traditional filtering.
- Query: When a user issues a query, it is first converted into an embedding using the same model used during ingestion. This query vector is then used to search the database for the most semantically similar vectors (nearest neighbors), which are then returned with their associated original content.
but there is important point, Create embeddings for each chunk, store those chunk-vectors in the vector DB.At query time, retrieve only relevant chunks and send only those to the LLM
So the “art” is mostly in the chunking strategy.
chunking, but in practice they are mostly text splitter classes/functions that you call in your code.
So it is not some magical separate service. It is more like:
load text
pass text to a splitter
get back chunks
Sometimes vector search alone is not enough,Example:invoice numbers,CNIC numbers,exact codes, in this case keyword search good, so sometime hybrid strategy use.
Full RAG pipeline end to end
You should clearly understand these stages:
data loading
cleaning
chunking
embedding
storing in vector DB
query embedding
retrieval
prompt building
answer generation
Metadata and filtering
This is very important in real systems.
Suppose you store:
title
source
date
category
language
city
property type
Then retrieval can be improved using filters like:
only Lahore properties
only recent docs
only legal documents
only Arabic documents
So learn:
what metadata is
how metadata improves retrieval
difference between semantic search and filtered search
Reranking
After retrieval, some systems use reranking.
Flow:
vector DB gets top 20 chunks
reranker chooses best 5
those 5 go to LLM
This improves precision.
pgvector is an open-source PostgreSQL extension ideal for smaller, cost-effective projects requiring SQL integration, while Pinecone is a managed, purpose-built SaaS vector database offering high scalability and low latency for massive datasets. Pgvector suits existing relational workloads, whereas Pinecone excels in enterprise AI, though it can be more expensive.
Key Aspects of RAG and Semantic Search
- Semantic Search Mechanisms: Uses vector embeddings to understand query meaning rather than just matching keywords, placing similar concepts near each other in a vector space.
- RAG Process: Involves two main components: a retriever (finds relevant data) and a generator (creates the response). It is highly efficient for accessing, for example, live social media feeds or frequently updated information.
- Data Chunking: Long documents must be broken down into smaller, meaningful segments to improve retriever accuracy.
- Hybrid Search: Combines keyword-based search with semantic, dense embedding search for superior, highly accurate retrieval.
- Memory and Context: Enhanced RAG systems can retain previous conversation context for more personalized, coherent interactions.
- Privacy and Security: RAG enables local embedding and retrieval, which reduces the need to send sensitive data to external APIs.
Now next understand:
chunking strategy
metadata
top-k retrieval
prompt building
hallucination/failure cases
hybrid search
reranking
evaluation
